Abstract
Underwater visual understanding has recently gained increasing attention within the computer vision community for studying and monitoring underwater ecosystems. Among these, coral reefs play an important and intricate role, often referred to as the rainforests of the sea, due to their rich biodiversity and crucial environmental impact. Existing coral analysis, due to its technical complexity, requires significant manual work from coral biologists, therefore hindering scalable and comprehensive studies. In this paper, we introduce CoralSCOP, the first foundation model designed for the automatic dense segmentation of coral reefs. CoralSCOP is developed to accurately assign labels to different coral entities, addressing the challenges in the semantic analysis of coral imagery. Its main objective is to identify and delineate the irregular boundaries between various coral individuals across different granularities, such as coral/non-coral, growth form, and genus. This task is challenging due to the semantic agnostic nature or fixed limited semantic categories of previous generic segmentation methods, which fail to adequately capture the complex characteristics of coral structures. By introducing a novel parallel semantic branch, CoralSCOP can produce high-quality coral masks with semantics that enable a wide range of downstream coral reef analysis tasks. We demonstrate that CoralSCOP exhibits a strong zero-shot ability to segment unseen coral images. To effectively train our foundation model, we propose CoralMask, a new dataset with 41,297 densely labeled coral images and 330,144 coral masks. We have conducted comprehensive and extensive experiments to demonstrate the advantages of CoralSCOP over existing generalist segmentation algorithms and coral reef analytical approaches.
The framework overview
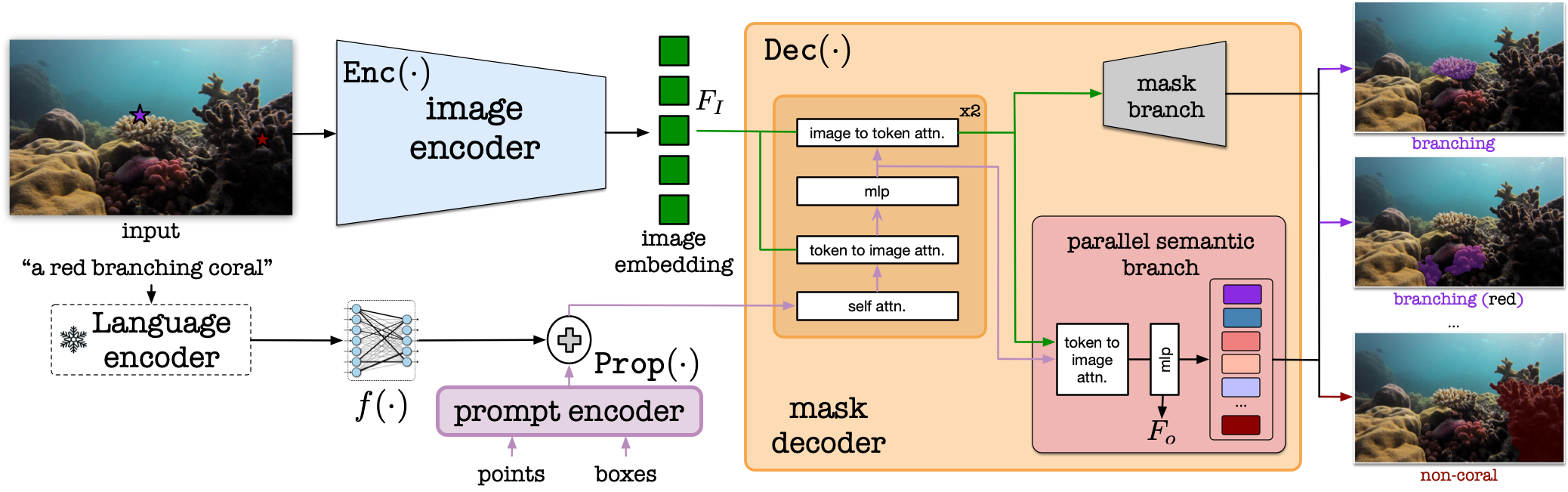
The proposed CoralSCOP framework. We design a parallel semantic branch inside the mask decoder, enabling the coral mask generation with semantics. The whole model is trainable in the pre-training procedure and Enc(·) is frozen in the tuning procedure.
We provide the detailed of our CoralSCOP under the pre-training procedure; user-defined tuning procedure; and instruction-following tuning procedure.
1) During the pre-training procedure, 1.3 million masks are utilized for training our CoralSCOP. We optimize the parameters of the whole model during the pre-training procedure to promote Enc(·) to extract underwater visual features. The composite prompts of point prompts and bounding box prompts are utilized for training.
2) For the user-defined tuning, the coral masks with corresponding user-defined semantic annotations are fed into CoralSCOP and we only optimize the MLP layer in Dec(·). The users could self-design the label of generated coral masks, ensuring the flexibility of the proposed CoralSCOP for downstream coral reef analysis tasks.
3) For the instruction-following tuning, we borrow the language decoder of CLIP to generate the textual embedding to empower CoralSCOP with the ability to understand the user intents. For coral mask generation, we only label the corals belonging to the given coral species when there are multiple coral species. The generated sentences are paired with the labeled images to formulate textual input and mask output pairs. Based on the coral species names, we asked ChatGPT-3.5 to generate 5 sentences to describe the distinctive appearances of such coral species. Then we pair such 5 sentences with the images from the corresponding coral species. We regard these textual inputs and coral mask outputs as positive pairs. We have also constructed the negative pairs to alleviate the hallucination, which means the generated coral mask does not match the given textual description. We randomly sample the textual descriptions from other coral genera to formulate the negative pairs considering the coral reef images from different coral genera share various appearance representations.
Qualitative Results
Comparisons between various algorithms

The coral segmentation comparisons between various algorithms. Both SAM and CoralSCOP could separate dissimilar corals into different coral masks while others failed.
The zero-shot generalization ability

The zero-shot generalization ability of CoralSCOP to coral reef images from various sites. The left side is the input image while the right side illustrates the coral segmentation result of CoralSCOP.
The robustness to the low visibility coral reef images
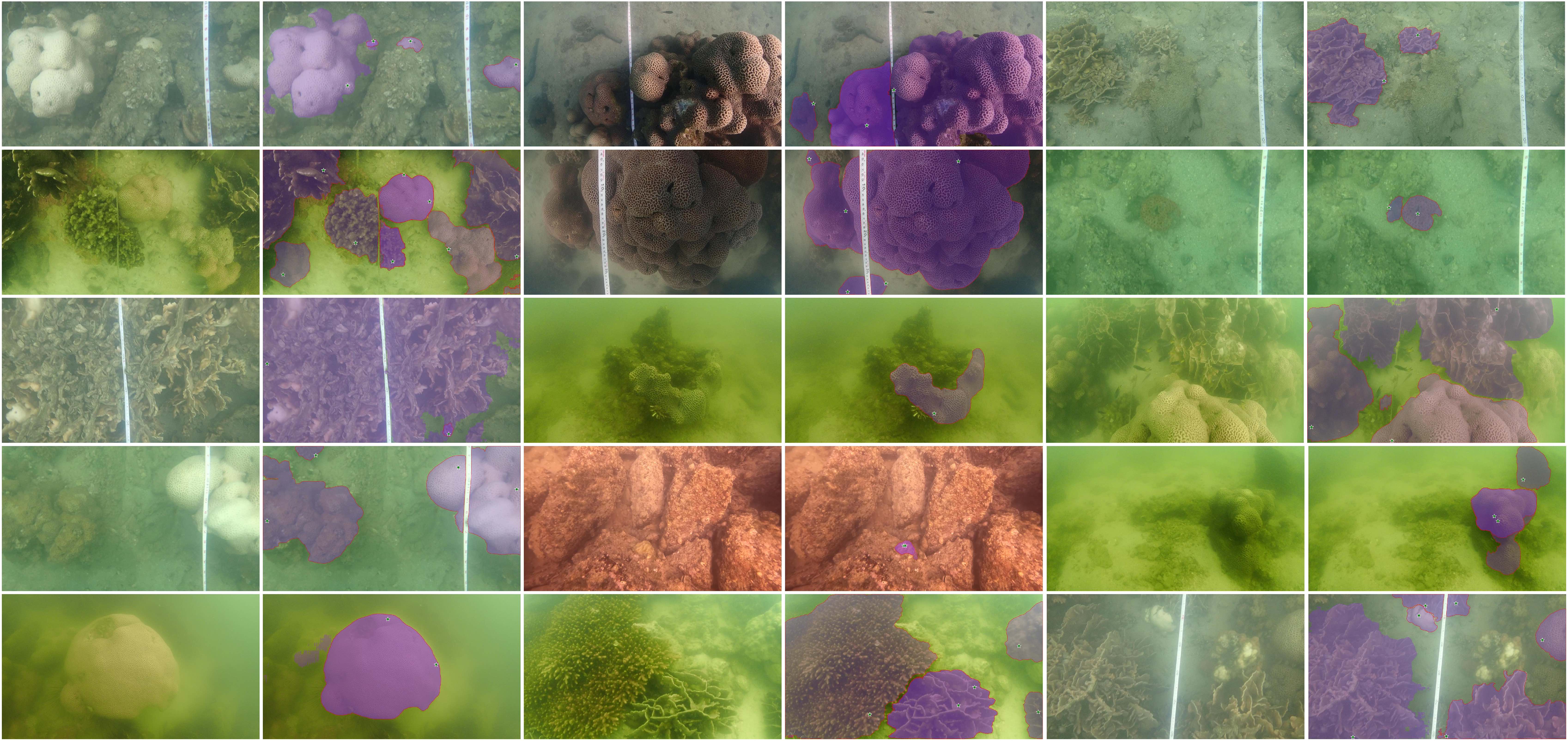
Our CoralSCOP demonstrates strong robustness to the low visibility coral reef images. The left side is the input image while the right side illustrates the coral segmentation result of our CoralSCOP.
Comparisons between SAM and CoralSCOP

We provide direct comparisons between SAM and CoralSCOP. SAM still suffers from the over-segmentation problem and cannot generate accurate and complete coral masks.
The sparse-to-dense conversion performance of various algorithms

The sparse-to-dense conversion performance of various algorithms. The CPCe results with sparse point annotations are also provided. Best viewed in color.
Citation
@inproceedings{ziqiang2024coralscop,
title={Coral{SCOP}: Segment any {CO}ral Image on this Planet},
author={Ziqiang Zheng, Haixin Liang, Binh-Son Hua, Yue Him Wong, Put ANG Jr, Apple Pui Yi CHUI, Sai-Kit Yeung},
booktitle={IEEE/CVF conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024},
}
Acknowledgement
We sincerely thank Gonzalo, Thomas, Yiheng Feng, Ruojing Zhou, Han Liu, Suzhen Fan, Maijia Li, Yuwen Zhang, Shou Zou, Yupei Chen, Yaofeng Xie, Jia Li and Kai Chen
for their help on data collection and processing. Without their efforts, we cannot finish this project on time. We also sincerely thank Gonzalo for his valuable feedback and practical suggestions that contributed to the development of the online tool.
